The Complete Guide to GPU Cloud Infrastructure (2026 Edition)
Jan 12, 2026
|
5
min read

Introduction
GPU cloud infrastructure is now central to AI innovation, real-time analytics, media rendering, financial computing, and enterprise digital transformation. What was once experimental is now mission-critical and choosing the right GPU stack, deployment model, cost structure, and cloud provider strategy can directly impact performance, agility, and TCO in 2026 and beyond. This guide equips you with the technical depth and practical insight needed to make precise infrastructure decisions.
Executive Summary
B300 (Blackwell Ultra) represents the next step in GPU cloud computing, prioritizing larger memory footprints and higher dense AI throughput for the largest foundation models
B200 is the current Blackwell baseline, offering strong performance for large-scale training and inference
H200 remains a balanced, production-ready GPU with wide ecosystem support
AMD MI300X delivers strong cost efficiency for memory-heavy workloads and inference-at-scale
The right GPU choice depends on model size, memory pressure, utilization, and software stack, not just TFLOPS
Table of Contents
What Is GPU Cloud Infrastructure?
Why GPU Cloud Matters Now
Latest GPU Architectures & What They Mean
3.1 NVIDIA Blackwell & Rubin
3.2 AMD Instinct & Competitors
3.3 Emerging Hardware Alternatives
Training vs. Inference – Architecture Differences
Cost, Performance & Workload Matching
Strategic Deployment Models
Industry Use Cases
Security, Reliability & Compliance
Choosing a GPU Cloud Provider
FAQs
Closing Thoughts & Future Trends
1. What Is GPU Cloud Infrastructure?
GPU cloud infrastructure delivers high-performance GPU resources on-demand via a cloud provider instead of on-premises hardware. GPUs specialize in parallel compute workloads such as deep learning, generative AI, simulation, and graphics unlike CPUs, which handle general serial tasks. Cloud GPU infrastructure abstracts hardware complexity while providing elasticity, regional availability, and operational agility.
2. Why GPU Cloud Matters Now
In 2026, the shift to GPU cloud is driven by:
AI at scale: Large models with billions to trillions of parameters require massive parallel compute that only modern GPUs provide.
Rapid innovation cycles: Teams spin up GPU clusters within minutes, instead of committing to long procurement cycles.
Cost flexibility: Pay-as-you-use avoids idle capacity and aligns spend with actual workload demand.
Global access: Distributed teams can deploy GPU compute close to users for low-latency inference.
3. Latest GPU Architectures & What They Mean
Modern GPU cloud infrastructure is not about one GPU fits all. It’s about selecting the right architecture for the workload.
3.1 NVIDIA Blackwell & Rubin
NVIDIA’s Blackwell architecture represents the latest generation of AI GPUs, delivering significant performance gains over previous models like H200 and H100 for both training and inference. Cloud providers are increasingly offering Blackwell B200 and GB200 configurations,and upcoming Blackwell B300 and GB300 which excel in large-model contexts due to high memory bandwidth and improved tensor cores.
Additionally, NVIDIA’s upcoming Rubin architecture (planned for late 2026) promises another leap up to 30 petaFLOPS FP4 performance with expanded memory capacities, directly benefiting trillion-parameter model workloads.
Tip: For large foundational models and GenAI training pipelines, prioritize providers with Blackwell / Rubin support.
3.2 AMD Instinct & Competitor Accelerators
AMD’s MI300X and newer Instinct family accelerators continue to gain traction for high-performance AI clusters. In some scenarios, AMD’s offerings with competitive memory bandwidth rival NVIDIA for throughput-oriented workloads, especially when integrated with ROCm ecosystem support.
Other emerging accelerators (including Chinese vendors) are starting to provide viable localized GPU cloud options, particularly in markets with data sovereignty requirements or cost-sensitive use cases.
3.3 Emerging Hardware Alternatives
Beyond traditional GPU families, purpose-built accelerators like Google TPUs are increasingly relevant for cloud AI workloads, especially inference at scale with major vendors improving ecosystem compatibility (e.g., PyTorch).
Similarly, upcoming solutions from Qualcomm (AI200/AI250) could shift inference economics with high memory capacities and efficient design geared for rack-scale deployments.
4. Training vs. Inference – Architecture Difference
AI training workloads prioritize raw parallel compute, memory bandwidth, and cluster scalability, while inference emphasizes latency, cost predictability, autoscaling, and memory efficiency. Designing infrastructure with this distinction ensures appropriate GPU selection and pricing strategy.
5. Cost, Performance & Workload Matching
Balancing cost and performance is central to GPU cloud strategy. Workload complexity, model size, and parallelism dictate instance choice whether reserved clusters for steady demand or spot instances for variable workloads. Competitive market pricing data (e.g., H100/H200 pricing) highlights how different providers shape price/performance dynamics in 2025.
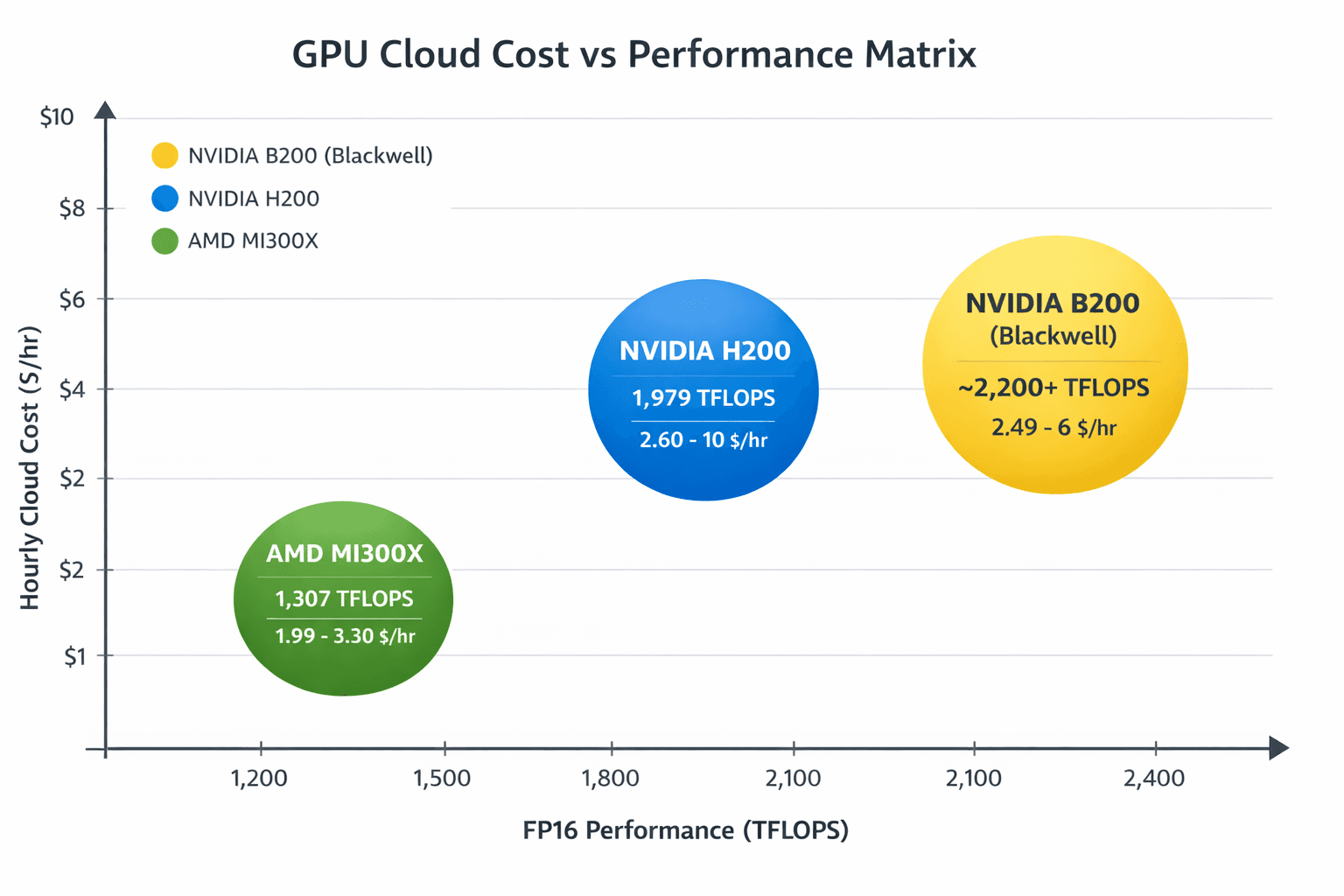
6. Strategic Deployment Models
Different organizations adopt GPU cloud in varying modes:
6.1 Virtual GPU Instances
Elastic and cost-efficient for mixed workloads.
6.2 Bare Metal GPU Pools
Dedicated hardware with full performance predictability (ideal for peak training).
6.3 Hybrid Architectures
Part on-prem / part cloud for latency-sensitive environments or regulated data.
Internal links:
Hybrid GPU Cloud Strategy (supporting blog)
7. Industry Use Cases
Real-world applications provide context for investment decisions:
Industry | GPU Use Case | Benefits |
FinTech | risk modeling, real-time analytics | precision + speed |
Media & AR/VR | real-time 3D rendering | throughput + scalability |
Smart Cities | video analytics | distributed inference |
Detailed examples and architectures are covered in related posts.
Internal links:
➡️ GPU Cloud for Media Rendering
➡️ Smart City AI Pipelines
8. Security, Reliability & Compliance
As GPU workloads grow, so do security and compliance needs from multi-tenant isolation to data residency and audit logging. Frameworks like MIG (Multi-Instance GPU) help isolate workloads, while advanced schedulers improve utilization without compromising safety.
9. How to Choose a GPU Cloud Provider
Selecting the right provider requires evaluating:
Hardware availability (latest GPUs & accelerators)
Network bandwidth & latency SLAs
Pricing & reserved instance options
Compliance and regional presence
Support for AI frameworks
Leverage benchmarking data and conduct proof-of-concept (POC) evaluations to avoid vendor bias.
10. Frequently Asked Questions
Q1: What’s better for AI training Blackwell or MI300X?
A: For many large-model workloads, Blackwell currently leads in raw throughput, while MI300X offers competitive performance with strong memory bandwidth. Provider availability also matters.
Q2: Are TPUs viable alternatives?
A: Yes, especially for inference workloads where price/performance and ecosystem compatibility align with TPU strengths.
Q3: How do GPUs impact inference latency?
A: Modern GPUs reduce batch latency and support autoscaling, essential for real-time services.
Closing Thoughts & Future Trends
GPU cloud infrastructure in 2026 is more than a utility, it's a strategic differentiator. Emerging architectures like Rubin, ecosystem shifts with TPUs and other accelerators, and competitive cost dynamics mean that CTOs must continuously reassess architecture and procurement strategies to stay ahead.

